[혼공컴운] Ch02. 데이터

강민철 - 혼자 공부하는 컴퓨터구조 운영체제
책을 읽으며 개인적으로 정리한 내용입니다.
목차
- 0과 1로 숫자를 표현하는 방법
- 0과 1로 문자를 표현하는 방법
✅ 0과 1로 숫자를 표현하는 방법
컴퓨터는 0과 1만 이해할 수 있다.
그렇다면 8, 100 등의 숫자는 어떻게 인식하는걸까?
⏺ 정보 단위
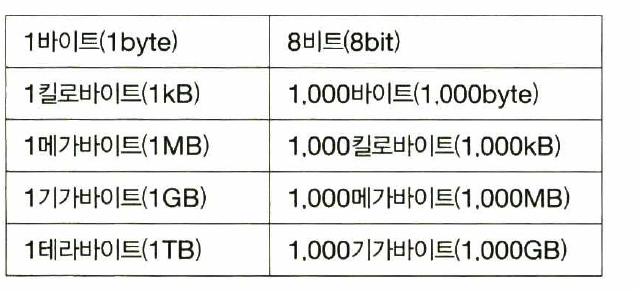
비트 : 컴퓨터가 이해하는 가장 작은 정보 단위 (0과 1을 나타냄)
바이트 : 8개의 비트를 묶은 단위
킬로바이트, 메가바이트, 기가바이트, 테라바이트는
이전 단위를1000개를 묶어 표현한 단위이다.
⏺ 2진법
0과 1로 모든 숫자를 표현하는 방법
숫자가 1을 넘어가는 시점에 자리올림을 한다.
((십진법은 0~9까지 표현하고, 9를 넘어가는 시점에 올림을 하는것))
컴퓨터에게 십진수를 알려주기 위해 - 십진수를 이진수로 표현한 값을 알려주면 된다.
2(10)+8(10) >> 10(2) + 1000(2) 를 보내면 컴퓨터는 이해할 수 있다.
숫자가 이진수인지 십진수인지 등을 그냥 읽었을 때는 알 수 없으므로
코드 상에선 ob를 붙혀서 표기한다.
ob1000 == 2진수 8
✔️ 2진수 음수표현
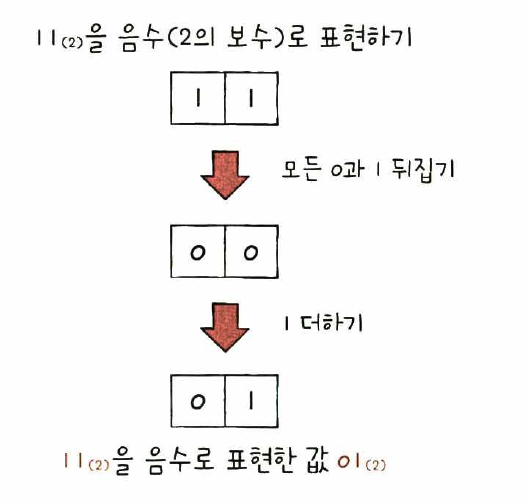
2의 보수로 표현할 수 있다.
2의 보수는 모든 0과 1을 뒤집고 거기에 1을 더한 값!!!으로 이해하는게 제일쉽다.
11(2)의 2의 보수를 구해보자.
>>> 00 + 1 = 01 (2의보수)
flag : 수가 양수인지, 음수인지 구분하기 위해 사용
컴퓨터내부에서 부가 정보가 필요하면 flag를 사용한다.
⏺ 16진법
2진법을 이용해 모든 숫자를 표현할 수 있지만 너무 길다.
그래서 16진법도 자주 사용된다.

왜 16진법을 사용할까?
2진수를 16진수로 16진수를 2진수로 변환하기 아주 간편하기 때문이다!
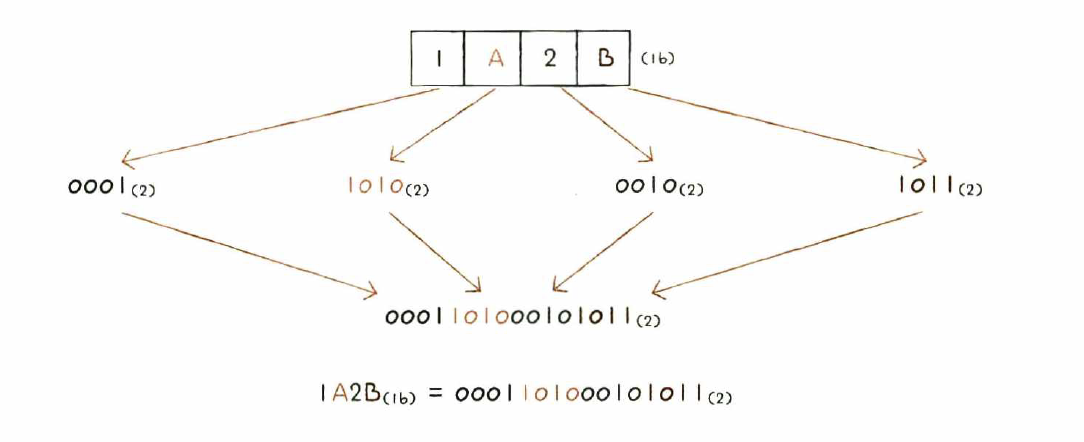
✔️ 16진수를 2진수로 변환
16진수를 이루는 숫자 하나를 이진수로 표현하면 4비트가 필요하다
16진수인 1A2B 는 다음으로 분리해서 2진수로 표현될 수 있다.
✔️ 2진수를 16진수로 변환
위와 딱 반대이다.
2진수 숫자를 4개씩 끊어, 그 숫자를 하나의 십육진수로 변환후 이어붙히면 된다.

✅ 0과 1로 문자를 표현하는 방법
컴퓨터는 0과 1만 이해할 수 있는데, 문자는 어떻게 이해하고 출력하는걸까?
⏺ 문자 집합과 인코딩
문자집합 : 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
> 문자집합에 속해있는 문자는 이해할 수 있다.
문자인코딩 : 문자를 0과 1로 변환해야 컴퓨터가 이해할 수 있다. 문자를 변환하는 과정을 문자인코딩이라 한다.
문자 디코딩 : 0과 1을 문자로 변환하는 과정
⏺ 아스키코드
ASCII : 초창기 문자집합
영어알파벳, 아라비아숫자, 일부 특수 문자의 포함
아스키 문자집합에 포함된 문자들은 7비트로 표현된다.
7비트 정보의 가짓수는 2^7개 (128)개의 문자를 표현할 수 있다.
>> 8비트중 1비트는 parity bit (오류 검출을 위해 사용하기 때문에 7비트까지만 표현할 수 있다)
아스키 문자는 0부터 127까지 숫자 하나에 대응되는데,
아스키코드를 이진수로 표현하면서 아스키문자를 0과 1로 표현하게 된다.
'A'는 십진수 65이고 - 이진수 1000001 로 인코딩된다.
'a'는 십진수 97이고 - 이진수 1100001로 인코딩된다.
*한글 등 다른 언어는 없다는 게 단점이고, 이를 극복하기 위한 인코딩 방식이 생겨났다.

⏺ EUC-KR
한글 인코딩 방식
한글은 초성, 중성, 종성의 조합이다.

1) 완성형 인코딩 방식
초중종의 조합으로 이루어진 하나의 글자에 고유한 코드를 부여하는 방식
> 가 : 1, 나 : 2 ....
2) 조합형 인코딩 방식
초성, 중성, 종성을 위한 비트열을 할당해 조합을 통해 하나의 글자 코드를 만드는 인코딩 방식
EUC-KR은 완성형 인코딩 방식이다!
초성, 중성, 종성이 모두 결합된 한글 단어에 -- 2바이트 크기의 코드를 부여한다.
2바이트= 16비트이기 때문에
EUC-KR로 인코딩된 한글은 4자리 16진수로 표현될 수 있다.

2350정도의 한글단어를 표현할 수 있다.
모든 한글 조합을 표현할 수 있는건 아니고, 이떄문에 생겨나는 문제가 종종 발생한다.
-> 마이크로소프트의 CP949가 EUC-KR을 확장된 버전으로 등장했지만.. 이마저도 한글 전체를 표현하기엔 넉넉하지 않았다.
⏺ 유니코드와 UTF-8
언어별로 인코딩을 나라마다 해야하면,,, 다국어 지원프로그램 만들 땐 모든 언어의 인코딩을 알아야하는 번거로움이 생긴다.
한국러/영어/일본어/중국어/ 독일어를 지원하는 웹사이트가 있다면..? 다섯개의 인코딩 방식을 알아야할까?
모든 나라 언어의 문자집합과 인코딩 방식이 통일되어 표준화되어있다면 이러한 수고를 덜 수 있다.
그렇게 나온것이 유니코드와 문자집합이다!!
대부분의 나라의 문자, 특수문자, 화살표, 이모티콘까지 코드로 표현될 수 있는 통일된 문자집합이다.
아스키코드나 EUC-KR은 글자에 부여된 값을 그대로 인코딩 값으로 삼았었지만,
유니코드는 글자에 부여된 값 자체를 인코딩 값으로 삼지 않는다.ㅏ
>> 다양한 방법 존재 (UTF-8, 16, 32 등)
✔️UTF-8
가장 대중적인 인코딩 방식
1바이트부터 4바이트까지의 인코딩 결과를 만들어낸다.
유니코드 문자에 부여된 값의 범위에 따라 인코딩 결과가 몇바이트인지 (1바이트~ 4바이트) 결정된다.

references
혼자 공부하는 컴퓨터구조 운영체제 (강민철)