
- 분류 전체보기 (585)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 1과목
- 공부일지
- 정보처리산업기사
- softeer
- 소프티어
- 파이썬
- kotlin
- SQL
- 문제풀이
- 데이터베이스
- 백준알고리즘
- BFS
- 시나공
- 백준 알고리즘
- 프로그래머스
- java
- 코틀린
- 코딩교육봉사
- MYSQL
- SW봉사
- 스프링
- python
- 코딩봉사
- 회고
- CJ UNIT
- C++
- 자바
- 백준
- programmers
- 알고리즘
- Today
- Total
JIE0025
SQL 파싱과 최적화, 옵티마이저, 실행계획 본문
✅ SQL 최적화
사용자가 SQL을 질의하면 옵티마이저(비용기반)는 그것을 가장 비용(cost)이 낮은 실행계획을 선택하여 프로시저로 만든다.
DBMS에서 프로시저를 작성하고, 컴파일해 실행가능한 상태로 만드는것이 SQL 최적화이다.
1) SQL을 파싱한다.
SQL 파서가 파싱을 진행한다.
- 파싱 트리를 생성한다 : SQL문을 이룽는 개별 구성요소를 분석해서 트리를 만든다.
- Syntax 체크 : 문법오류가 없는지 확인한다.
- Semantic 체크 : 의미상의 오류가 없는지 확인한다 (없는 테이블/컬럼 사용, 권한이 있는지 등)
2) SQL 최적화
- 옵티마이저가 최적화를 맡는다
- 미리 수집한 시스템/통계정보를 바탕으로 실행경로를 생성하고 가장 효율적인 1개를 선택한다.
3) 로우소스 생성
- 로우소스생성기가 담당한다.
- 옵티마이저가 선택한 실행경로를 실행가능한코드(프로시저)형태로 포매팅한다
✅ 옵티마이저
옵티마이저는 DBMS의 핵심엔진으로
최적의 데이터 액세스 경로를 선택해준다.
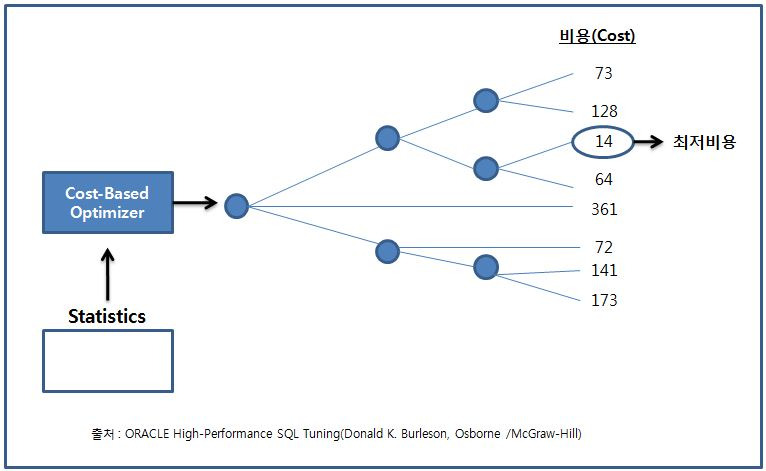
1. 쿼리를 수행하는데 후보군이 될만한 실행계획들을 찾아낸다.
2. 데이터 딕셔너리에 미리 수집해둔 오브젝트 통계 및 시스템 통계 정보를 이용해 실행계획의 예상비용을 산정한다.
3. 최저 비용을 나타내는 실행계획을 선택한다.
⏺ Execution Plan
DBMS로 Execution Plan (실행계획)을 통해서 경로를 미리 볼수있다.
테이블 전체 스캔 하는지, 인덱스 스캔하는지 확인할 수 있고 Cost값도 확인해볼 수 있다.
* Cost : 쿼리를 수행하는 동안 발생할것으로 예상하는 I/O횟수또는 예상 소요시간이다 .
⏺ 옵티마이저 힌트
옵티마이저는 자동으로 자기가 효율적일것 같은 실행계획을 선택하는데
옵티마이저 힌트를 이용해 데이터 액세스 경로를 바꿔줄수도 있다.
/*+ */ 주석뒤에 +를 붙히면 힌트를 사용할 수 있다.
SELECT /*+ HINT1 HINT2(...) */ 컬럼목록
FROM 테이블명
WHERE 조건;
INDEX(A, A_X01) INDEX(B, B_X03) --> O
- 힌트안에 인자 나열시엔 , 를 사용할 수 있다.
INDEX(A, A_X01), INDEX(B, B_X03) --> X
- 힌트 사이에 , 를 사용하면 안된다.
SELECT /*+ FULL(SCOTT.EMP) */ --> X
- 테이블 지정시엔 스키마명까지 명시하면 안된다.
SELECT /*+ FULL(E) */ --> O
FROM EMP E
- FROM절 테이블에서 ALIAS(별칭) 을 사용했으면 힌트에도 ALIAS사용해야 한다.
힌트는 여러 유형에서 줄 수 있는데,
한개만 지정할수도 여러개를 세세하게 지정할수도 있다.
-- 테이블 전체 스캔을 강제
SELECT /*+ FULL(emp) */ empno, ename, deptno
FROM emp
WHERE deptno = 10;
-- 병렬 처리 degree 8 제안
UPDATE /*+ PARALLEL(emp, 8) */ emp
SET sal = sal * 1.05
WHERE hiredate < DATE '2000-01-01';
조인 순서·방식·인덱스 지정 복합
SELECT /*+
LEADING(d e) -- dept 먼저 조회
USE_NL(e d) -- emp→dept 중첩루프 조인
INDEX(e emp_empno_idx) -- emp.empno_idx 인덱스 강제 사용
*/
e.empno, e.ename, d.dname
FROM dept d
JOIN emp e
ON d.deptno = e.deptno
WHERE d.loc = 'NEW YORK';
왜 힌트를 복합해서 사용할까?
지피티를 이용해서 위의 힌트를 해석해보라 했다.
그렇게 디테일한 이해는 안되더라도 일단 읽어보는 정도로만 학습하자.
- ‘dept → emp’ 순서가 작은 부서부터 필터링한 뒤,
- ‘인덱스 Nested Loop’ 조인으로 emp에서 소수의 행만 읽도록 하면
- FULL JOIN이나 HASH JOIN보다 I/O가 줄어든다
- 실제로 비용이 낮아지는 경우가 많다
- LEADING(d e) → 먼저 dept 테이블만 스캔
- 옵티마이저에게 “먼저 dept를 읽어서 d.loc = 'NEW YORK' 조건을 적용하라”고 제안
- 결과적으로 dept 테이블 전체(예: 수백 블록)가 아니라, NEW YORK 인 부서만 담긴 아주 작은 서브셋(예: 1–2블록)만 읽게 된다.
- 필터된 dept 행 수만큼만 조인 드라이버(outer) 로우가 생성
- 예를 들어 NEW YORK 부서가 3건만 있다고 가정하면, 이제 조인할 outer 행은 3건뿐이다.
- 이 3행에 대해서만 inner 테이블(emp)을 탐색하게된다.
- USE_NL(e d) → Nested‐Loops 조인 강제
- outer에서 한 행 꺼낼 때마다 inner를 인덱스로 찾아 들어간다.
- 반대로 해시 조인이나 병렬 스캔이었다면 emp 전체(수천 블록)를 한 번에 읽어야 할 수도 있다.
- INDEX(e emp_empno_idx) → 인덱스 범위 스캔/진입
- emp_empno_idx는 일반적으로 emp(deptno) 컬럼에 걸려 있는 작은 구조(예: 수십~수백 블록)이다.
- Nested‐Loops가 inner를 탐색할 때,
- 인덱스 블록(branch + leaf) 몇 블록만 읽고
- 나온 ROWID로 실제 데이터 블록을 1행당 1블록씩 참조한다.
- 만약 Outer 행 3건에 대해 emp에서 매번 5건씩만 매칭됐다면,
- 인덱스 읽기: (branch+leaf) 약 3–5블록
- 데이터 블록 접근: 3행 × 5건 = 15블록
- —> 총 약 20블록 정도만 I/O 발생
- 비교: 힌트 없을 때 가능한 플랜
- 옵티마이저가 HASH JOIN을 택했다면,
- dept(작으니 괜찮지만)
- emp 전체 스캔: 수천 블록 읽기
- 또는 FULL(emp) 플랜에서 emp만 스캔해도 수천 블록.
- 옵티마이저가 HASH JOIN을 택했다면,
힌트는
최적화목표, 액세스방식, 조인순서, 조인방식, 서브쿼리팩토링, 쿼리변환, 병렬처리, 기타 .... 가 있다고한다.
디테일하게는 이후 학습실습하면서 알아가도록하자.
* 힌트는 옵티마이저에게 건내는 제안이고, 옵티마이저가 힌트대로 처리하지 않을수도 있다.
* 정말 빨라졌는가를 검증해줘야한다.
'Application > Database' 카테고리의 다른 글
| DB 메모리 영역 SGA (Shared Pool, DB BufferCache, Redo Log Buffer 를 알아보자. (0) | 2025.04.28 |
|---|---|
| DB 클러스터링, Active-Standby, Replication (0) | 2024.12.31 |
| [MongoDB] _id를 제거할 수 있을까? (0) | 2023.06.04 |
| [MongoDB] Collection과 Document를 생성하고 실습해보자 (0) | 2023.05.28 |
| [NoSQL] MongoDB란? 맥북(M1) 몽고디비, compass 설치 (0) | 2023.05.28 |



