
- 분류 전체보기 (570)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- programmers
- 문제풀이
- 코딩봉사
- 데이터베이스
- kotlin
- MYSQL
- 백준 알고리즘
- 스프링
- 정보처리산업기사
- 회고
- 코딩교육봉사
- python
- SW봉사
- CJ UNIT
- C++
- softeer
- 알고리즘
- BFS
- 자바
- 백준
- 코틀린
- 프로그래머스
- 소프티어
- java
- SQL
- 공부일지
- 백준알고리즘
- 파이썬
- 시나공
- 1과목
- Today
- Total
JIE0025
[MySQL] 순위 함수 (분석 함수) 본문
순위함수(분석함수)
결과에 순번, 순위를 매기는 함수
비집계함수 중 RANK, NTILE, DENSE_RANK, ROW_NUMBER 등이 해당된다.
PARTITION BY : 동일 그룹으로 묶어줄 칼럼 명 지정
ORDER BY : Partition 정의에 지정된 컬럼에 대한 정렬 수행
| SELECT <순위함수이름> (arguments) OVER ([PARTITION BY <partion_by_list>] ORDER BY <order_by_list>) FROM 테이블명; |
종류
| NTILE() : PARTITION을 지정된 수 만큼의 등급으로 나누어 각 등급 번호를 출력 |
| RANK() : 순위 값 중 동등 순위 번호는 같게 나오고 그 다음 순위를 다음 번호를 뺀 그 다음 값을 출력 |
| DENSE_RANK() : 순위 값 중 동등 순위 번호는 같게 나오고 그 다음 순위를 다음 번호로 출력 |
| ROW_NUMBER() : 동등 순위를 인식하지 않고 매번증가되는 번호를 출력 |
| LEAD(expr [,offset] [,default]) / LAG() : 지정된 칼럼의 이전, 이후의 행 값을 출력 |
| FIRST_VALUE() / LAST_VALUE() : 각 그룹별 첫 번째와 마지막값 하나만출력 |
| CUME_DIST() : 주어진 그룹에 대한 상대적인 누적분포도 값을 반환한다. 분포도 값(비율)이므로 반환 값의 범위는 0 초과 1이하 사이의 값을 반환한다. |
순위 함수를 사용해보자
1) ROW_NUMBER() : 동등 순위를 인식하지 않고 매번증가되는 번호를 출력
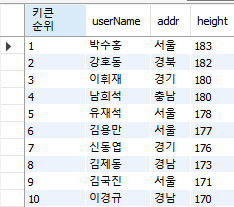
키 큰 순위로 정렬하기
ROW_NUMBER() 를 사용해서 값이 같더라도 증가시켰다.
OVER(ORDER BY height DESC) : height 기준으로 내림차순(큰값>작은값) 정렬
| USE cookDB; SELECT ROW_NUMBER() OVER(ORDER BY height DESC) "키큰순위", userName, addr, height FROM userTBL; |
1-2) ROW_NUMBER()
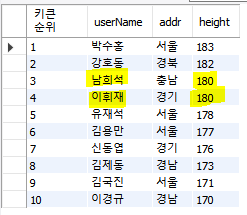
키가 같은 경우 가나다순 정렬시키기
| USE cookDB; SELECT ROW_NUMBER() OVER(ORDER BY height DESC, userName ASC) "키큰순위", userName, addr, height FROM userTBL; |
1-3) ROW_NUMBER()
각 지역별 순위 매기기
PARTITION BY를 사용해서 지역별로 순위를 나누어주었다.
| SELECT addr, ROW_NUMBER() OVER(PARTITION BY addr ORDER BY height DESC, userName ASC) "지역 별 키큰 순위", userName, height FROM userTBL; |

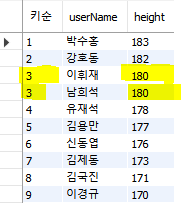
2) DENSE_RANK : 순위 값 중 동등 순위 번호는 같게 나오고 그 다음 순위를 다음 번호로 출력
키가 같을 때 동일한 등수로 처리하기
| SELECT DENSE_RANK() OVER(ORDER BY height DESC) "키순", userName, height FROM userTBL; |
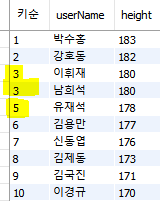
3) RANK() : 순위 값 중 동등 순위 번호는 같게 나오고 그 다음 순위를 다음 번호를 뺀 그 다음 값을 출력
동점으로 3등이 2명일 때 그 다음 높은 키는 5등이 되게 하기
SELECT RANK() |
4-1) NTILE() : PARTITION을 지정된 수 만큼의 등급으로 나누어 각 등급 번호를 출력
전체 인원을 키순 정렬 후 2개의 그룹으로 분할
| SELECT NTILE(2) OVER(ORDER BY height DESC) "반번호", userName, addr, height FROM userTBL; |
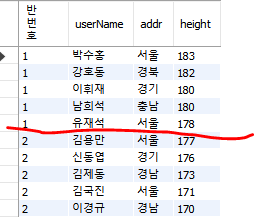
4-2) NTILE()
4개의 반으로 분리하기
| SELECT NTILE(4) OVER(ORDER BY height) "반번호", userName, height FROM userTBL; |
4개로 분리할 때엔 아래와 같이 3 3 2 2 로 나뉘어지는 것을 확인 할 수 있다.
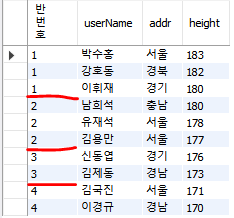
6개로 분리하면, 1,1,2,2,2,2개로 분리된다.
5) LEAD(컬럼 [,값을 가져올 행의 위치] [,기본값]) : 다음 행의 값 찾기
값을 가져올 행의 위치 기본값 = 1, 생략가능
기본값, 생략가능
회원 테이블(userTBL)에서 키가 큰 순으로 정렬한 후 다음 사람과의 키 차이구하기
| SELECT userName, height, height - (LEAD(height,1,0) OVER(ORDER BY height DESC)) as "다음 사람과 키차이" FROM userTBL; |
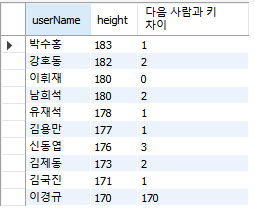
6) FIRST_VALUE : 각 그룹별 첫 번째와 마지막값 하나만 출력
지역별로 가장 키가 큰 사람과 키차이 구하기
| SELECT addr, userName, height, height - (FIRST_VALUE(height) OVER (PARTITION BY addr ORDER BY height DESC)) AS "지역별최대키와 차이" FROM userTBL; |
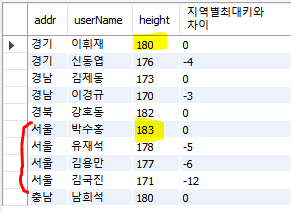
7) CUME_DIST() :
주어진 그룹에 대한 상대적인 누적분포도 값을 반환한다.
분포도 값(비율)이므로 반환 값의 범위는 0 초과 1이하 사이의 값을 반환한다.
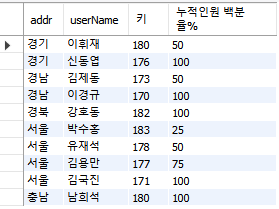
같은 지역 회원과 비교해 키가 크거나 같은 사람이 전체의 몇% 인지 누적 백분율 확인하라.
| SELECT addr, userName, height AS "키", (CUME_DIST() OVER (PARTITION BY addr ORDER BY height DESC)) * 100 AS "누적인원 백분율%" FROM userTBL; |
'Application > Database' 카테고리의 다른 글
| [MSSQL] CASE 표현식 (0) | 2021.04.14 |
|---|---|
| [MSSQL] 술어와 연산자, 연산자 우선순위 (0) | 2021.04.14 |
| [MySQL] 오류 발생해도 계속 삽입하도록 설정하기, 중복시 덮어쓰기 (0) | 2021.04.13 |
| [MySQL] 데이터 삭제 DELETE, DROP, TRUNCATE (0) | 2021.04.13 |
| [MySQL] 데이터 변경 UPDATE (0) | 2021.04.13 |



