
- 분류 전체보기 (570)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- MYSQL
- SW봉사
- 스프링
- softeer
- 백준 알고리즘
- java
- kotlin
- 정보처리산업기사
- 시나공
- 알고리즘
- 코딩봉사
- 백준알고리즘
- 파이썬
- C++
- 공부일지
- SQL
- programmers
- 데이터베이스
- 프로그래머스
- 소프티어
- BFS
- 1과목
- 회고
- python
- 코딩교육봉사
- 백준
- 코틀린
- 문제풀이
- CJ UNIT
- 자바
- Today
- Total
JIE0025
[코딩테스트] 문자열 다루는 방법 정리 (python) 본문
✅ 코딩테스트에 나오는 문자열 문제 유형
- 회문(Palindrome)
- 문자열 뒤집기
- 조건에 맞게 재정렬
- 특정 단어 추출
- 애너램 (anagrams) : 문자를 재배열해 다른뜻을 가진 단어로 바꾸는것
- 가장 긴 팰린드롬 찾기
⏺ 회문(Palindrome)
회문 (팰린드롬) 이란?
- 앞 뒤가 똑같은 단어나 문장
- 대소문자와 띄어쓰기는 구분하지 않는다.
- 글자와 숫자만 따진다
- 가나다다나가
- Madam, I'm Adam
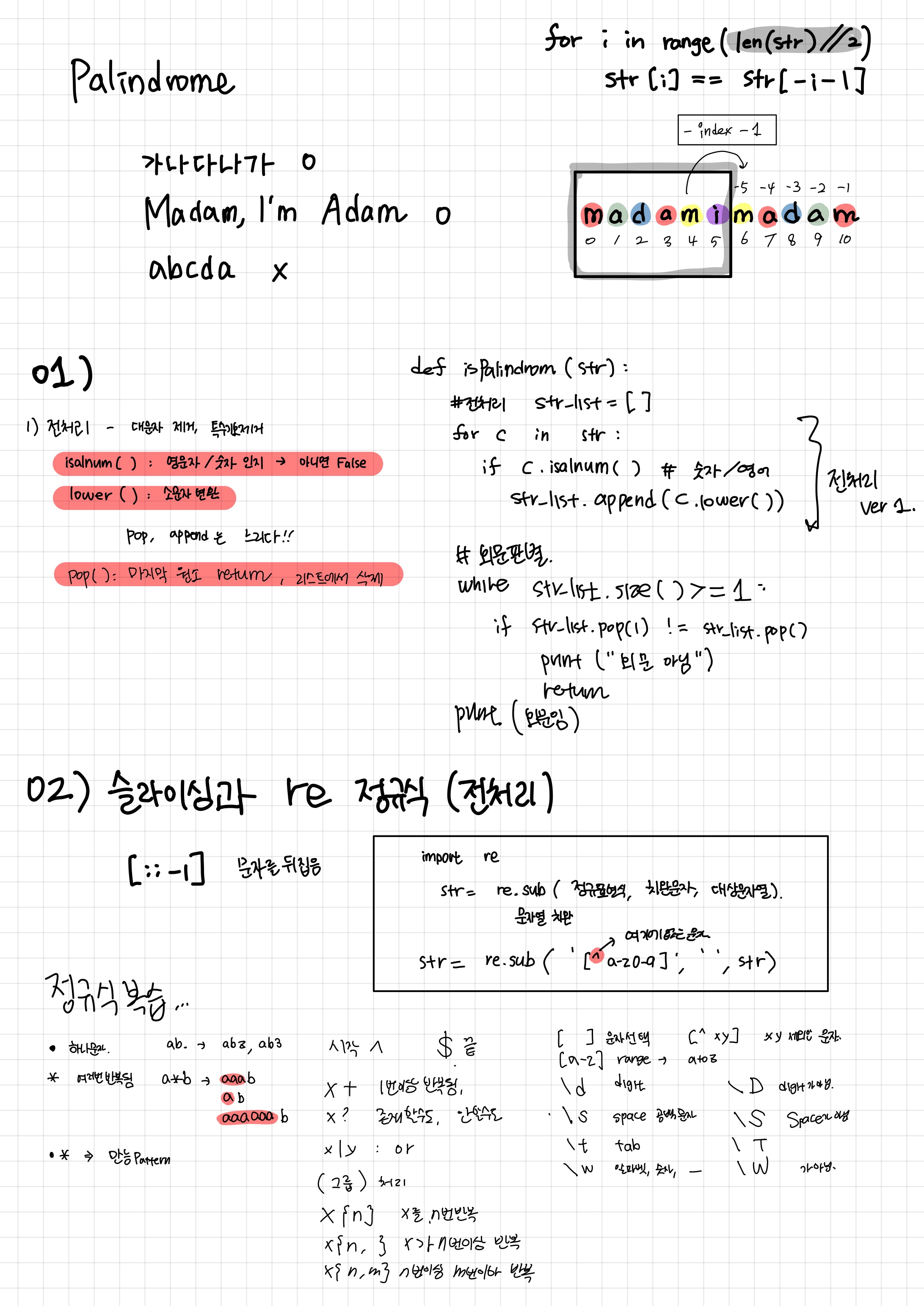
re.sub('패턴', '바꿀문자열', '적용할문자열')
💻 팰린드롬 판별 여부 코드!
>> V1은 리스트의 크기를 조절하는 append(), pop()을 사용하기 때문에 느리다.
>> V2 슬라이싱을 이용한게 훨씬 빠르다
#팰린드롬 공부
import re
def isPalindromeV1(str) :
#전처리
strlist = []
for char in str:
if char.isalnum():
strlist.append(char.lower())
print(strlist)
#팰린드롬
while len(strlist) > 1:
if strlist.pop(0) != strlist.pop():
print("팰린드롬이 아니다.")
return
print("팰린드롬이다.")
def isPalindromeV2(str) :
#전처리
str = str.lower()
str = re.sub('[^a-z0-9]','',str)
print(str)
#팰린드롬 확인
if str == str[::-1]:
print("팰린드롬이다.")
else:
print("팰린드롬이 아니다.")
print("-----using list-----")
isPalindromeV1("abcda")
isPalindromeV1("Madam, I'm Adam")
print("-----using slice and regex-----")
isPalindromeV2("abcda")
isPalindromeV2("Madam, I'm Adam")
⏺ 문자열 뒤집기
리스트 내부의 문자열을 뒤집는 방법
1) 리스트의 reverse()함수 사용
a = ['a','b','c','d']
a.reverse()
print(a)
# ['d', 'c', 'b', 'a']
2) 슬라이싱 [::-1]
str = "abcde"
print(str[::-1]) #edcba
3) 투포인터
처음과 끝 인덱스를 변수로 지정, 인덱스를 이동해가면서 조작하는 방식
def reverseStringWithTwoPointer(str):
left, right = 0, len(str)-1
while left < right:
str[left], str[right] = str[right], str[left]
left +=1
right -=1
print(str)
a = ['a','b','c','d']
reverseStringWithTwoPointer(a)
⏺ 조건에 맞게 재정렬
sort 의 key를 이용해 정렬 조건에 따라 정렬해주는 유형!
이것이 코딩테스트다 ch06 정렬을 공부했으니 쉬운 유형이다.
https://jie0025.tistory.com/407
리스트 안에
회원의 아이디, 회원가입날짜, 사용자가 쓴 댓글들이 아래와 같이 구성되어 있다고 하자.
data = ["hanpy 20101213 재미없다 235 재미있다", ...]
💻 각각의 DB의 회원들을 댓글들 중에 숫자를 제거하고,
댓글들을 정렬한 후에,
가입한 날짜 순으로 재정렬하라.
어떻게
- isalpha 문자인지 판별하는 함수
- isdigit 숫자인지 판별하는 함수
⏺ 특정 단어 추출
- Counter로 개수 추출
- most_common이라는 함수가 있지만 hit를 제외해야하기 때문에 사용할 수 없어서 dict 정렬을 통해 가져왔다
💻 Hit를 제외한 단어중 가장 많이 등장하는 단어를 뽑는 코드를 작성하라
단 대소문자는 구분하지 않고, 구두점은 무시한다.
paragraph = "Bob hit a ball, the hit BALL flew far after it was hit"
import re
from collections import Counter
def findNumWord(str):
#전처리 : , 삭제 + 소문자 치환 후 각 단어를 리스트에 할당
str_list = list(re.sub('\W' ,' ', str ).lower().split())
#Counter를 이용해 각 단어 개수 세기 (카운터는 dict를 확장하고 있다.)
nums = dict(Counter(str_list)) #dict로 치환
# nums = {'bob': 1, 'hit': 3, 'a': 1, 'ball': 2, 'the': 1, 'flew': 1, 'far': 1, 'after': 1, 'it': 1, 'was': 1}
#nums = sorted(nums, key = lambda x : nums[x])
#이 방법도 있지만 직관적으로 몇개인지 잘 안보이므로 아래 방법을 사용했다.
# nums.items() == dict_items([('bob', 1), ('hit', 3), ('a', 1), ('ball', 2), ('the', 1), ('flew', 1), ('far', 1), ('after', 1), ('it', 1), ('was', 1)])
nums = sorted(nums.items(), key = lambda item : item[1], reverse=True)
print(nums[1][0])
paragraph = "Bob hit a ball, the hit BALL flew far after it was hit"
findNumWord(paragraph)
>> ball
⏺ 애너그램 (anagrams)
문자를 재배열해 다른뜻을 가진 단어로 바꾸는것
💻 아래와 같이 입력값을 넣었을 때,
알파벳 순서를 바꾸면 같은 값이 되는 것들끼리 묶어서 출력되는 알고리즘을 작성하라
입력값 : ["eat","tea","tan","ate","nat","bat"]
출력값 : [["bat"],["nat","tan"],["ate","eat","tea"]]
💡 각각의 단어를 sorted했을 때 같은 애들끼리 묶어주면 된다.
def anagrams(input_data):
result = []
# dict()를 만든다. 키값으로 sorted단어를 넣는다.
# value에는 리스트를 주고, 원래 단어를 append한다.
groups = dict()
for word in input_data:
sorted_word_list = sorted(word)
sorted_word = ''.join(c for c in sorted_word_list)
if sorted_word in groups:
groups[sorted_word].append(word)
else:
groups[sorted_word] = [word]
#리스트 길이(개수)별 정렬
values = groups.values()
result = sorted(values, key = lambda x : len(x))
for item in result:
item.sort() #각 리스트 내부 영문 오름차순 정렬
return result
input_data = ["eat","tea","tan","ate","nat","bat"]
result = anagrams(input_data)
print(result)
#output_data = [["bat"],["nat","tan"],["ate","eat","tea"]]
⏺ 가장 긴 팰린드롬 찾기
주어진 문자열에 존재하는 많은 팰린드롬 중 가장 긴 팰린드롬을 찾는 방법은?
인덱스를 0부터 끝까지 하나씩 위치를 이동해가면서 팰린드롬을 확인하는 방법이 최선
data = 'ewqpbewqbfjabcdefedcbaienqnfkndkl'
정답은 abcdefedcba
data = 'ewqpbewqbfjabcdefedcbaienqnfkndkl'
length= len(data)
if data == data[::-1] or length <2:
print(data)
exit(0)
maxValue = ""
for i in range(length):
for j in range(length, i, -1):
tmpData = data[i:j]
if tmpData == tmpData[::-1]: #팰린드롬이므로
if len(maxValue) < len(tmpData):
maxValue = tmpData
print(maxValue)
# abcdefedcba
'Algorithm' 카테고리의 다른 글
| [알고리즘] 위상정렬 알고리즘 (Topology Sort) 공부 (0) | 2023.02.10 |
|---|---|
| [최단경로] 플로이드워셜 python (0) | 2023.01.25 |
| [이것이코딩테스트다] ch6 정렬 (0) | 2023.01.24 |
| [이것이코딩테스트다] ch4 구현 (0) | 2023.01.21 |
| [이것이코딩테스트다] ch3 그리디 (Greedy) (0) | 2023.01.21 |


